Handling backend/network failures for mobile applications


While Bonnie said this for people, I feel this is equally valid for mobile apps. Things go wrong in mobile apps with a remote backend all the time. Mobile networks are unreliable; Backend, Content Delivery Networks (CDNs), and even Mobile Operating Systems (OS) can sometimes misbehave. When things go wrong, the mobile app can crash, it can show an ugly error to customers and earn the much-deserved 1-star rating, or the app can change how to react to these stimuli and become the app customers love.
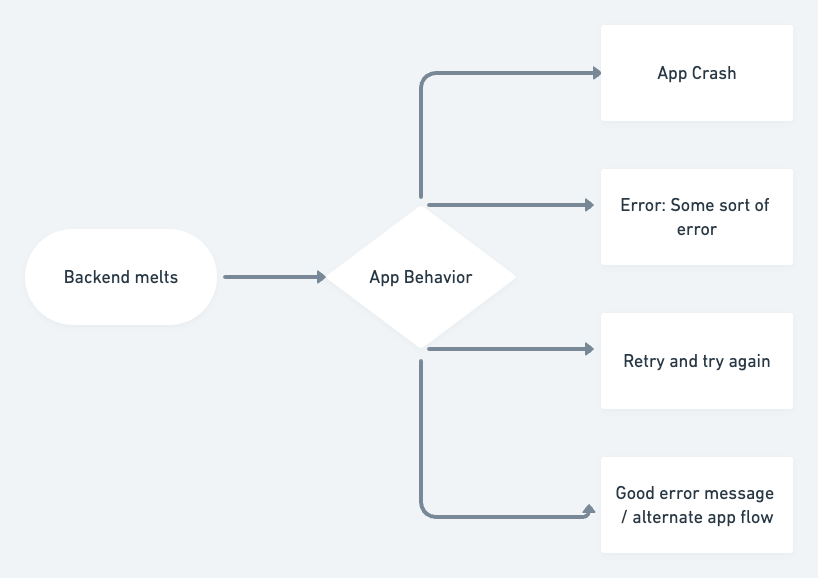
While I have written most of this article keeping mobile developers in mind, I hope web developers can draw parallels easily and others in the technology ecosystem would appreciate the difference between a hackathon project and a good product.
Retries
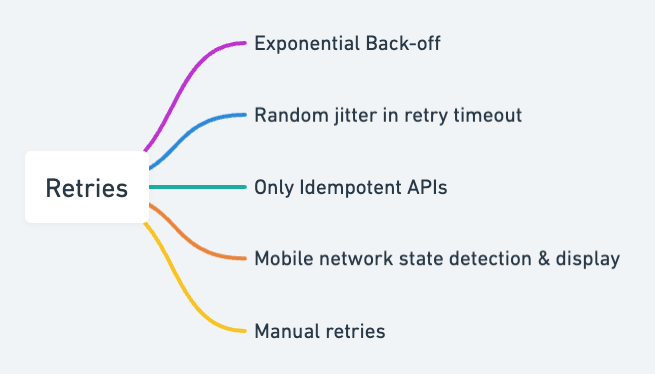
Retrying requests made to Backend when the requests time out or get an error is the first thing that comes to our mind while developing apps. The requests can fail for multiple reasons, including network failure, CDN failure, and backend failure. And that's one of the reasons I don't always recommend retries by default; we don't even know if the retries would be suitable for the backend.
If you plan to introduce retries, make sure you have some exponential and random back-off built-in. If a backend service faces difficulty and the clients keep retrying indefinitely, the backend service may never recover from this failure.
While it's obvious to most developers, I want to note that we should consider automated retries only for idempotent APIs. For example, a payment request can be successful in a payment process, but your app lost the mobile network while the Backend sent a successful response.
In some cases, even exponential back-off is dangerous for a failing backend, and you should show a manual retry button instead of automated retries. Let the human be the factor that introduces randomness to retries.
It usually makes sense to show customers that you are retrying if you are retrying. If the retry is because of their phone not having an active network connection, then it again makes sense to show this fact.
Circuit breaker

Backend developers use circuit breakers all the time, and if they already know a call to an upstream service will fail, they short circuit the call. These short-circuited calls don't waste network bandwidth & CPU cycles and return a fallback response. As mobile developers, we should follow this method and see if the application can continue when an API is continuously failing. This also forces us to think about blocking and essential APIs and corresponding UI elements as they are compared with optional APIs, information, and UI elements.
While automated and manual retries are apparent solutions, in some cases, your application may choose to ignore the response of a particular API. For example, if you are loading multiple cards in a Facebook-like feed and one of the APIs fails, you can choose not to show that card.
Error messages

Do your APIs have well-defined and well-understood error code responses? If you rely only on HTTP status code for displaying errors, you may miss out on the 'perfect error message' for your customers.
Errors can happen at your Backend (application/input errors), the Backend may misbehave, and the API gateway or CDN may report an issue. The errors can also happen because of an inconsistent state within the application.
Let's say your customer searched for a product on your website and your API failed to fetch results because of a database connection issue. Instead of giving zero results answer to clients, you should throw an error. The client can then choose to retry automatically and present customers with an error message and a retry button.
There are two principles I think about when writing error messages:
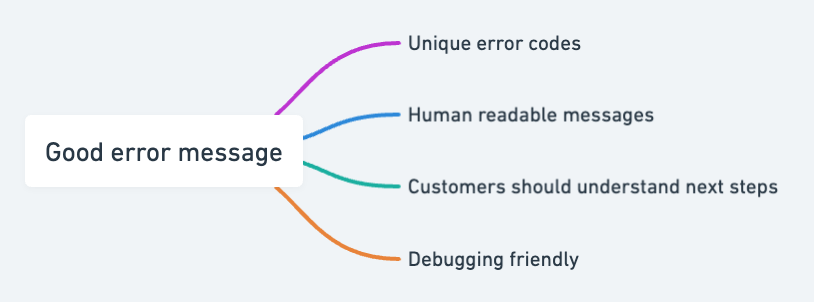
1. When the customer sees the error message, do they know what they can do to unblock themselves (it could include calling your customer care number)
2. When your customer support team or engineers receive a screenshot of the message, can they trace and debug the error?
State management

A lot of mobile application code is about managing the state and making changes to UI based on the current state. API failures or network failures should be part of this state machine for any mobile application.
Instead of writing error handling as a huge if / else block or exception handling block, make it a state change and let your app's UI display errors to customers accordingly.
I had colossal API failure %age on mobile applications reduced to less than half when we displayed the current network state (offline/online) to customers along with a retry button.
Analytics

If you already have API performance analytics for your mobile application, you are already in a good place. Google's firebase SDK automatically collects analytics around failed / timeout APIs. API performance analytics is often valuable data. I still create custom analytics events for some APIs so that my team and I can quickly catch failures.
Custom events and alerts based on client-side analytical events become crucial in some cases - login failures, video playback failures, and purchase or checkout failures are just some examples. In one case, adding a "Report a bug" call to action on an error screen reduced the number of incoming calls for my support team and we got significantly more logs and data about application state with the addition.
Test for failures
It's okay to write code that will fail gracefully. We often test for functionality, and I want to emphasize how it's equally (if not more) essential to test for failures. It's easy to mock failure responses with different codes and delayed responses. It's also easy to simulate bad/slow network conditions. Tools like http://httpstat.us/, Charles Proxy, and custom code can simulate and automate these conditions.
Additionally, if your team does chaos testing, testing for mobile client behavior during backend chaos testing becomes a handy tool in your arsenal.
Rest of the armory
If your backend application is behind a CDN and your CDN supports fallback / always-on responses based on the upstream application state, consider using this tool. In the past, I have generated hourly static responses for some of the popular APIs for my applications (in one case, this included a search and filter page).
On occasions, I had also asked customers to restart the app when multiple manual retries failed. Nothing is better than resetting the state and starting with a clean slate for a buggy application. I did send a custom analytical event for all such retries and restarts.

Remote config often comes in handy when a particular feature / API takes time to recover. When things go wrong, remote configs may not work as desired, so you should choose the default configurations carefully. You can disable that feature for all customers or a set of customers.
Does your network stack consider these failure points and solutions? I hope when you are writing a network stack for your next mobile application, you will consider some of the problems and solutions described in this post.
Thank you friends
Thanks to all the friends who have helped me understand this topic better. This post has gone through multiple drafts, and many of my friends have given me some great feedback on the post. Thank you, Manideep Polireddi, Saikat Mitra, Prachi Sharma, Piyush Gupta, Ashutosh Agrawal, and Ankush Dharkar. I have used your words and phrases liberally in this post.