Going from zero tech team members to 300


While recording a podcast with Scaler, Arnav Gupta asked a question I have received in multiple forms from founders and engineering leaders connecting with me for advice. What changes when your team goes from zero to 300? I have seen this journey numerous times and some good and bad implementations along with the journey. Here is how I will design tech, processes, and teams next time I take this journey.
Mandatory Disclaimer: My current take is likely to change as I try more things and learn more. I haven't worked with super large teams and don't know what works there. My limited experience and discussions with other engineers have given me this perspective. It may or may not work for you. Your industry, country, product scale, engineering to ops ratio, etc., may invite some problems sooner or later than what I have described here. In short - YMMV!
Another Disclaimer: Many of these topics deserve multiple blog posts; hence, a couple of sentences per topic necessarily loses fidelity and my ability to express my thought process well. Feel free to disagree, but please be kind. I miss several points like remote, async communication, sprint demos, design docs, architecture council, etc.
Inflection points
Technology, organization design, complexity, and process evolve continuously in a growing startup. I have seen the following big inflection points, five engineers, 15 engineers, 50 engineers, 120 engineers, 200 engineers, and 300 engineers.
It's worth repeating that your inflection points may be different, but it's good to recognize the problems at each stage to decide if a change is needed.
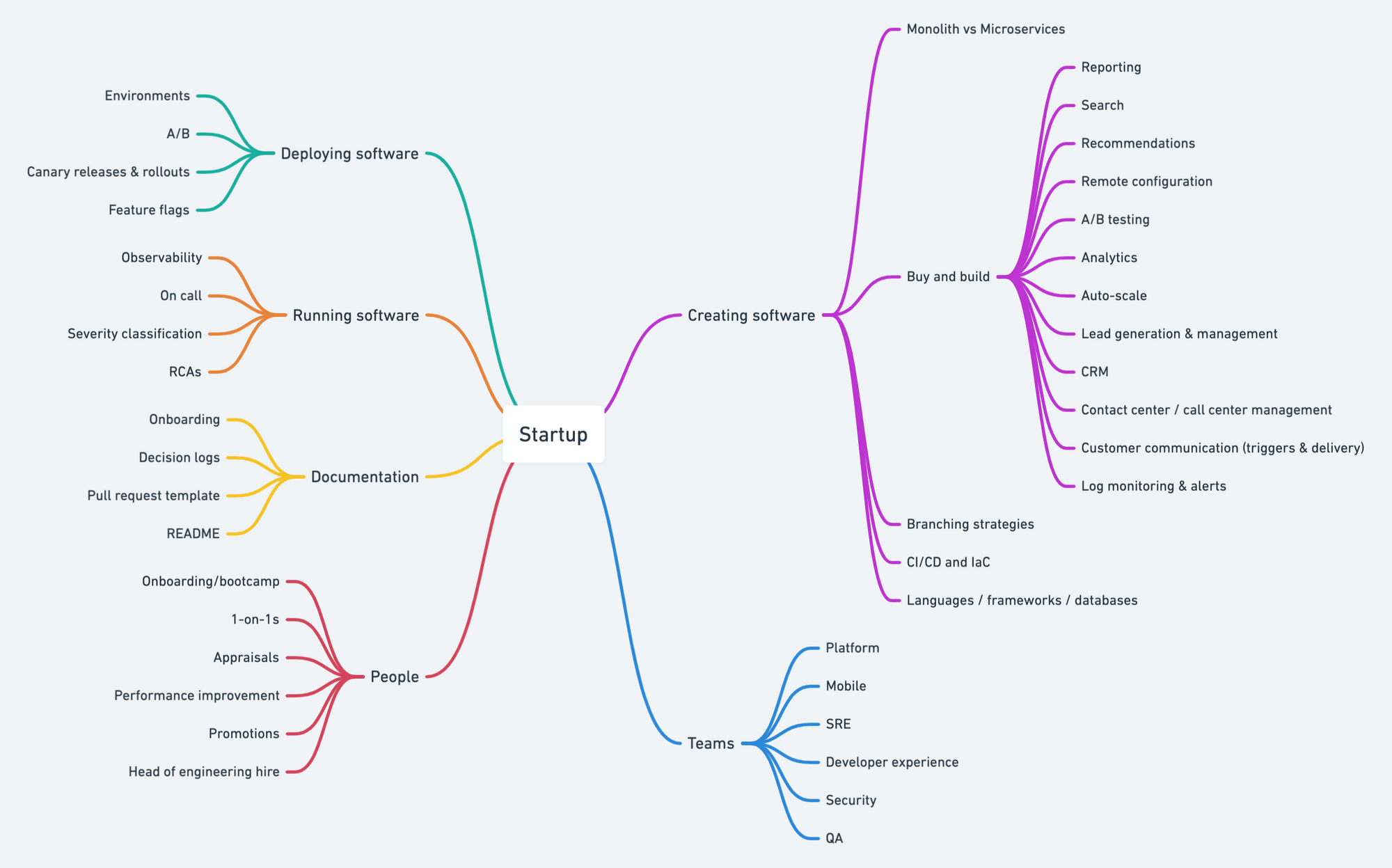
Creating software
Monolith -> Microservices
I almost always advise founders to start with a monolith and move fast. Once they have established product market fit and have started to hire more than 15 engineers, the microservices journey starts becoming inevitable. In some cases, I have gone from a single monolith to multiple monoliths before taking the microservices journey. Monolith to microservices transition seems like a mixture of science and craft, but there are plenty of examples for us to follow.
Some smells might tell you that your organization or product is now too big for a monolith. Your release velocity has decreased primarily because of regressions from one change part of the code impacting another. Your engineers regularly say, "I don't know about that part of the code."You feel there are parts of the code that no one owns, and nobody wants to change.
Some of your services get significantly more traffic than others, but you end up scaling the full service anyway. One engineer is unable to fully onboard a new engineer.
Buy and Build
Buy vs. build decisions change based on your team size, product complexity, and scale. While initially, I recommend teams to skew towards buying most of the solutions- as the team and product scale, it starts making sense to build some of them in-house. Here is a non-exhaustive list of services that I have bought first and then built in-house:
- Analytics ingestion ( client events and change data capture)
- Search
- Recommendations
- Remote configuration
- A/B testing
- Analytics & reporting
- Auto-scale
- Lead generation & management
- CRM
- Contact center / call center management
- Customer communication (triggers & delivery)
- Log monitoring & alerts.
I don't think the scale and team size heuristics work for these decisions. I have moved to in-house CDC at 40 person team, in-house lead management at 60, and in-house A/B testing at 80 member team. At the same time, I bought lead generation and CRM software when I had more than 150 engineers in a group.
You must ensure your team is not falling into the 'Not Invented Here' trap while evaluating and integrating third-party solutions. At the same time, third-party software may introduce stringent processes. When your business and engineering teams have to start doing acrobatics around the answer, it's time to evaluate moving some of the products in-house.
Do remember that even the most prominent companies end up using third-party software. e.g., Amazon uses Fastly and not just their CDN. In another example, Amazon was also using Oracle till 2019.
Branching strategies
I have primarily used gitflow or a variant of gitflow so far, but multiple experts have told me that trunk-based development is the only way to go as team size becomes more considerable.
CI / CD and IaC
While many startups can live without CI/CD easily, even with 50-60 engineers, I have recommended setting up CI (if not CD) from day 1.
My take on Infrastructure as Code is similar, you can probably live without IaC even with 100s of engineers, but this debt is tough to repay later on. Terraform is mostly a defacto standard if you are on the cloud.
Languages / frameworks / databases
I always start with Python, Django, MySQL, and DynamoDB for small projects and startups building their MVP. There are enough worthy candidates like Ruby on Rails, Next.js, Flask, and Springboot. My only recommendation here is to not go for Golang, C++ type languages for the first versions of the product unless performance and IO bottlenecks are the core focus of your product.
The questions I ask the teams are following:
- Which language/frameworks/database are you most familiar with and will give you maximum velocity?
- Which framework makes it easy to hire developers?
- Which framework is easy to pick for new hires?
These questions and recommendations are rooted in the belief that frameworks don't matter until the startup reaches product market fit and starts scaling. This belief also means I am not opposed to startups doing k8s from day one if their team is most comfortable with k8s, and they will have to learn packer, ansible, or other methods from scratch.
Beyond MVP, I often recommend a uniform language/framework across the company to ensure anyone can contribute to any service. In a microservices environment, it's tempting to have small teams choose their languages and frameworks. We must repeat all the tooling, boilerplate code, monitoring, and alerting integrations for all the framework combinations. Small groups can save a lot of time by sharing the same best practices across the company.
At 120 and 200 engineers, I had as many as five languages in my teams based on the use case (data engineering, batch or real-time recommendations, image processing, API composites, stream processing, etc.)
Teams
Platform team
I have felt the need for someone doing platform and shared libraries work in teams as small as 5. In most of my groups, someone took an interest, wrote the first shared libraries, built developer experience tools, etc.
I have managed to carve out a small, dedicated platform team focusing on developer productivity at team sizes of 50 so far. I am sure others have done it sooner too.
Mobile teams
Mobile teams are slightly different from the larger engineering organization I have defined. The equivalent of platform teams for the mobile team starts making sense even at a small group of 10 (a single repository probably plays a role).
We started with a central team every time I managed a mobile unit. Each pod got dedicated mobile engineers working with them only when the mobile team size reached 15+, and we had more than five pods.
The platform team becomes critical at this point because they remove duplication by writing shared libraries, working on automated builds, and setting up concurrency, UI, and other guidelines.
SRE team
For my small teams (1-30), I almost didn't have anyone dedicated to DevOps or for SRE. Everyone was responsible for creating and managing the infrastructure and uptime of their service(s). With IaC and proper monitoring, some responsibilities of early SRE teams can be taken care of by the larger team.
In some cases, I ended up combining the DevOps and SRE responsibilities within the same team, where the SRE team also took over Devops tool development responsibility.
Not having a dedicated SRE team gave more ownership to my developers but also took time away from what some people considered "real engineering." I can't entirely agree with this group and would not feel like a separate SRE team until I have reached a 200+ team size and have mission-critical services that need exceptional engineering for uptime.
Developer tools and developer experience team
Developer experience is another team that doesn't exist in many startups, but someone is doing the job all along. I have carved out this team at 50, 80, and 150 in different environments. However, I was as late as 250 member team in one instance before making a case for a dedicated team to improve productivity and reduce friction in development and deployment.
Security team
I have often taken help from external security consultants for code reviews and penetration testing, even for small teams. If you have a product that's seeing any traction, do look at application and infrastructure security.
So far, I had only hired dedicated in-house security (and later compliance) team after a team size of 120 when it was essential for us to automate some of the security policy enforcement and have developers get access to experts during the design and development process.
tl;dr - Don't ignore security even if you don't want to hire a full-time in-house team yet.
QA team
My take on the QA team's existence is rapidly changing. For small groups, I don't hire QAs and rely on developers + founders to do all the automation and testing.
For larger teams (50+), I have hired SDETs for service automation, integration test automation, manual testing, and building test automation harness.
My current recommendation is to get developers to do all automation (including integration tests) and hire a small set of experts to build test automation and data management tools. Any client-side quality testing should be the team's primary responsibility of developers and product managers. I recommend hiring a small group of manual testers from crowd testing companies for the best results.
Independent teams
In my opinion, the quickest way to slow down a development team is to make them dependent on another team. I have made this mistake multiple times, first by mistake and later because I couldn't find any other way.
As much as possible, start making teams with specific customers and goals. Microservices sometimes shine in keeping teams from stepping on each other's toes.
Deploying software
Environments
Surprisingly, the environment is a topic I haven't fully solved yet. In one of my teams, every QA engineer got a dedicated test environment for automation and manual testing. Running so many environments was very expensive, and we found multiple ways to save money (e.g., shutting down all QA environments on night/weekends).
Development, QA, staging, pre-production, and production are popular environments, and most teams I have worked with use a combination of these.
I have seen use cases within the pre-production and staging environment where we staged only front-end changes. Internal teams used the staged environment before promoting front-end changes to end customers.
Multiple environments are not easy to maintain- security, permissions, correct test data, server versions, etc., become complicated as the number of services and software complexity increases.
While I haven't solved the problem yet, my current attempt is to reduce the number of environments and use ephemeral environments with automation.
A/B
I recommend using a third-party A/B service from the beginning to enable the correct measurement of product changes and hypothesis testing. I have written full-fledged A/B testing service only after crossing a team size of 80 and 200; I often thought we didn't have to build it from scratch.
Canary release & rollouts
Canary releases are not practical for startups running two machines. Unless each of your services runs on 50-100 nodes, a 5% canary release is very costly (feasible but costly).
I have followed %age rollouts for mobile applications, and for some features, I have also done this for backend applications (with feature flags).
Feature flags
While feature flags are a staple in trunk-based development, I have regularly used them for backend and mobile applications. I recommend them for most teams (you can quickly start with third-party feature flag software before building something in-house).
Like all good things in life, it's easy to overdo feature flags but don't be afraid and use the goodness.
Running software
Observability
It pays to invest in observability early on. I have been in situations where our website was on the first page of hacker news, and we failed to scale- and I got no automated alerts. I came to know about the failure from friends.
Most cloud resources and k8s are easy to monitor, and a simple Prometheus + Grafana setup is suitable for most startups. APMs like DataDog and NewRelic also allow you to set up alerts on metrics and logs.
I recommend investing in monitoring and alerting when you start making revenues. Paying clients don't like downtime.
On call
I set up my first on-call roaster at a team size of 5. When I set up multiple pods, I again have an on-call roster for each team and a common central on-call. I have made the joint on-call decision twice and joined a common with this in place; some engineers don't like this, and I understand why. I still like the mechanism because it allows engineers to understand the whole business. This construct probably breaks down beyond a team size of 500.
Severity classification
My engineers made a t-shirt "Make P0 great again"; I got my signal. We had to find a way to classify which bugs or issues would block a release and which ones won't. Which production issues are big enough that CEO should know about them, which ones should we rush to fix any time of day or night, weekday or weekends, and which ones can we get to on Monday morning?
While your classification and limits may change, I have used ranges similar to this:

Of course, you must also set up these limits for individual products (e-commerce companies) or courses (for ed-tech startups). Unpublish these products if they are causing issues.
In some cases, I have seen a different company-wide classification and a higher level team-wide classification for production issues. I haven't exercised this one extensively.
RCAs
I am a big fan of learning from RCAs (root cause analysis). Start early; as soon as you have on-calls, start improving the quality of RCAs. For teams bigger than 50, it makes sense for senior engineers and managers to review RCAs in a team setting. You want to share learning with others and maintain rigor in the process.
Documentation
Decision logs
Most small teams take decisions together, and they are well communicated to everyone instantly. I have seen this breaking as soon as I hit a team size of 20. Start maintaining a lot of all your big and small engineering decisions, which other options your team considered, what were the advantages and disadvantages of each choice and why you made a particular decision.
As your team grows, you must revisit some decisions; 50, 120, and 200 team size inflection points are often a good place to review these decisions.
Pull request template
The contents of a pull/merge request need attention from day 1. A PR with screenshots of UI, test cases, requirements, and answers to obvious questions from reviewers ensures PRs don't keep going back and forth. That's an often missed document that I recommend teams to adopt early on.
README for each code repository
I have joined multiple teams where people gave me a code repository without instructions for setting up a functional local development environment. It's both disappointing and wastage of time. I have often asked my teams to prepare a small README for their repository within two weeks of us checking in the first code.
People
Onboarding/Bootcamp
When your software is small, it's accessible to onboard new engineers. But as the whole stack becomes complex, you must invest in technical onboarding documents. When you have a 200-engineer team with multiple pods, the number of channels, mailing lists, and developer dashboards/tools a new engineer needs to know is significant. The onboarding is also team specific. Automate this process if possible. Onboarding documents, new joiner-friendly tasks, and a new engineer playground help people get started.
I once worked with a team with a three-month extensive onboarding Bootcamp. I soon felt the itch to code and escalated this to my CEO. I recommend a 1-2 week Bootcamp for larger teams (200+) to get new joiners familiar with the code, engineering culture, and expectations.
1-on-1s
I am a big fan of these meetings. Even if the structure of these meetings is ad-hoc and engineers don't know how to make the best use of these meetings- I still recommend all founders to start these discussions from 1st month. Any engineering managers you hire should start meeting their teams 1-on-1 with a pre-defined schedule and cadence.
As teams grow, I space out how frequently I have met my skip-level reports twice so far. I have resorted to publishing my calendar and picking random team members to talk to because I couldn't meet everyone every quarter.
Create a culture of 1-on-1 discussion with direct and skip-level managers to continuously understand your team's needs.
Appraisals
For small teams, founders have a good understanding of contribution, potential, criticality, and budgets, so it's relatively easy to have good enough appraisals where the team is satisfied. As soon as the team size crossed 10-15, I started to put together each level's engineering levels, roles & responsibilities, and how regular 1-on-1s would fuel appraisal discussions.
Performance improvement
I don't know anyone who enjoys putting their team members on a performance improvement program (PIP) where the failure outcome is parting ways. But I have had to formulate and execute PIPs in teams as small as 50. I hope you will have a better hiring, mentoring, and 1-on-1 process than mine, and you can delay this. It still helps to articulate when someone should be recommended for PIP, how it's communicated and how the outcome is measured as soon as you see the first signs of this happening.
Promotions
I have seen and done Adhoc promotions in small teams of even 30 to 50 people, but I think my team paid for this mistake with their career (I am sorry about this). I now request all my managers to understand their organization chart to find holes their team members can fill, give them additional responsibility and promote them if someone can do an excellent job at the next level.
CTO / Head of engineering hire
Many startups begin without an engineering hire. If you think an in-house engineering team can play a massive role in the success of your startup, please hire one soon. I don't have first-hand experience working with a startup without an engineering head, so I can't say much about what you are missing.
I hope this post can serve as a checklist and reference for growing startups. Scaling up teams is both challenging and exciting. I learn more about this topic whenever I join a new company, advise a friend's startup, or scale my teams. Remember, change is the only constant.